
Historia
Jupyter surge en 2014 como una evolución del proyecto IPython, una potente consola para Python. Sin embargo, Jupyter es mucho más ambicioso que IPython, se pretende construir una plataforma que ofrezca a los científicos un conjunto de potentes herramientas para trabajar con datos, visualizarlos y poder compartir los resultados.
El origen  de su nombre es un homenaje a Galileo, al que se considera autor del primer “paper” científico de astronomía de la era moderna en 1610, en el cual describe sus observaciones astronómicas a través de un telescopio de las lunas de Júpiter. Galileo demostró que la Tierra orbita el Sol de la misma manera que las lunas de Júpiter orbitan dicho planeta.
de su nombre es un homenaje a Galileo, al que se considera autor del primer “paper” científico de astronomía de la era moderna en 1610, en el cual describe sus observaciones astronómicas a través de un telescopio de las lunas de Júpiter. Galileo demostró que la Tierra orbita el Sol de la misma manera que las lunas de Júpiter orbitan dicho planeta.
El proyecto fue iniciado por Fernando Pérez, un científico y profesor de la Universidad de California Berkeley. Sin embargo, el proyecto es software libre y está basado en componentes libres, por lo que está apoyado, desarrollado y mantenido por una amplia comunidad.
La adopción y el éxito de Jupyter ha sido muy grande, de tal modo que se está convirtiendo en un standard para el trabajo de los científicos de datos. Hoy en día la herramienta está integrada algunas de las plataformas y entornos más importantes y extendidas como Google Cloud, Microsoft Azure, AWS, IBM Bluemix, Databricks Platform, GitHub, Rackspace, Continuum,Jetbrains.
¿Cómo funciona Jupyter?
Jupyter nos ofrece una shell interactiva vía web, a la que podemos acceder desde un navegador. La shell está organizada en pequeños bloques, cada bloque puede contener texto arbitrario formateado en Markdown, fórmulas matemáticas en LaTeX, código en multitud de lenguajes, resultados, gráficos, vídeos, widgets o cualquier elemento multimedia.
Podemos escribir código de programación en estas celdas e ir ejecutándolo paso a paso o todo de golpe, obteniendo todos los resultados parciales. También podemos usar los bloques de texto para documentar el código o añadir las explicaciones oportunas, que pueden contener enlaces, imágenes, vídeos u otros elementos.
Esta serie de piezas de código, notas y resultados se guardan en un notebook, que es un fichero que contiene toda esta información. Uno de los principales objetivos de Jupyter es fomentar y simplificar la compartición de conocimiento y resultados a través de los notebooks. Plataformas como GitHub o Databricks Community Edition facilitan esta tarea. De esta manera los notebooks pueden ser fácilmente difundidos y los resultados pueden ser reproducidos y validados en diferentes entornos. Por supuesto esto es muy útil para la divulgación y la formación o en entornos educativos.
Jupyter soporta integración con más de 40 lenguajes de programación en los que podemos escribir el código de nuestro notebooks, por ejemplo Python, R, Scala, Ruby o Go. Pero también es fácilmente integrable con herramientas y plataformas de Big Data como Spark, lo que permite abstraerse de la complejidad de estas herramientas, aprovechando todo su potencial desde un entorno muy amigable.
Una forma muy sencilla de probar Jupyter es a través de Try Jupyter!, una página hospedada por Rackspace que nos ofrece una instancia de prueba donde podemos ejecutar algunos notebooks de ejemplo o escribir los nuestros propios.
Instalación
Lo primero que necesitamos es tener instalado Python 3, que podemos descargar de su web oficial. Una vez hecho, actualizamos vía terminal el gestor de paquetes de Python e instalamos Jupyter. Al arrancarlo, se abrirá una nueva ventana en nuestro navegador predefinido, y la terminal quedará bloqueada con el proceso. Podemos abrirlo en otro navegador, para lo cual se nos indica la URL en la salida por pantalla.

Creando un cuaderno
Como arrancamos Jupyter desde la terminal, se abrirá el workspace en la carpeta en la que estemos (que generalmente será nuestro home de usuario). Es conveniente saber que no permite navegar a carpetas superiores a la inicial. Con el botón New, podemos crear:
- Carpetas (recomendable para organizar todo).
- Archivos de texto (con un editor bastante simple).
- Terminales.
- Cuadernos, que es la opción que vamos a estudiar en este tutorial.
Cuando creamos un cuaderno, se nos abre en una pestaña nueva. La interfaz es muy sencilla, con una barra de menú y herramientas y una celda vacía, que es la unidad básica de trabajo con Jupyter. En una celda, podremos escribir una o varias líneas de código, y ejecutarla. También podemos escribir texto plano, y eliminar la celda del flujo de ejecución del cuaderno o hacer que se muestre de manera diferente si queremos que funcione como título, separador de sección, etc. Lo veremos más adelante.
Es importante remarcar que tenemos dos modos de trabajo en Jupyter:
- Edición, que permite modificar el contenido de las celdas, como si fuera un editor de texto. La celda que tengamos seleccionada se muestra en verde. Podemos entrar en el mismo seleccionando una celda y pulsando Enter.

- Mando, que nos permite ejecutar celdas o modificar el cuaderno y su estructura. La celda seleccionada se muestra en azul. Podemos volver al modo de mando pulsando Esc.

Para ejecutar una celda, haremos Control + Enter, o si queremos pasar automáticamente a la siguiente después de ejecutarla, podemos hacer Shift + Enter. Para saber cuándo una celda se ha ejecutado, está en ello o ya ha terminado, podemos mirar la cabecera de la celda:
- Si solamente aparece In [ ], quiere decir que aún no se ha ejecutado.
- Si lo que tenemos es In [*], entonces está en proceso de ejecución.
- Si aparece un número entre los corchetes, ya ha terminado de ejecutar. La única pega es que podemos haber hecho cambios posteriores a su ejecución, y esto no se indica de ninguna manera.
Todos los atajos de teclado disponibles están en el botón

Escribiendo código
Es importante, a la par que evidente, tener instalados los paquetes de Python que queramos utilizar. Una vez hecho, podemos importarlos al cuaderno. Para los ejemplos utilizados en este tutorial, será necesario instalar los paquetes matplotlib, numpy y emoji. Recuerdo que la instalación de los mismos se hace igual que instalamos jupyter al principio del tutorial, es decir:
|
1
|
pip3 install matplotlib
|
Podemos escribir cualquier tipo de algoritmo, como podría ser una búsqueda binaria:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
|
def busqueda_binaria(array, valor):
ary = array
a = 0
b = len(array)
while a < b:
m = (a + b) // 2
if array[m] == valor:
return m
elif array[m] < valor:
a = m + 1
else:
b = m
return None
x1 = [0,1,2,3,4,5,6,7]
x2 = [1,4,8,12,41]
x3 = [0,1,2,4,8,16,32]
|
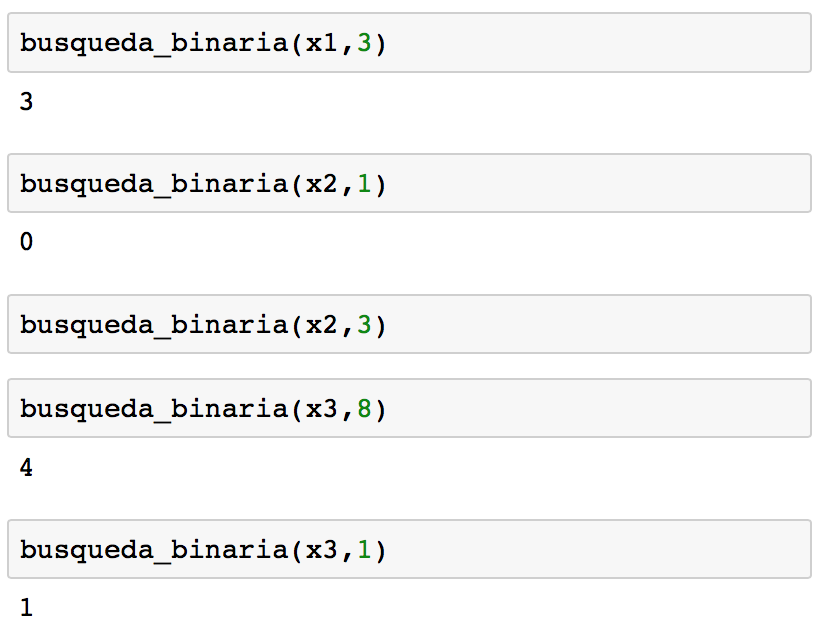
LaTeX
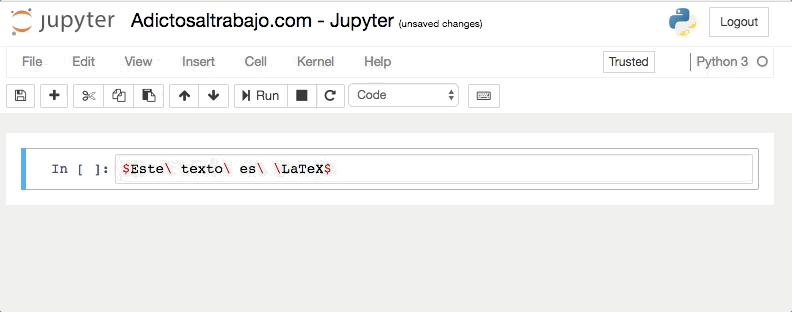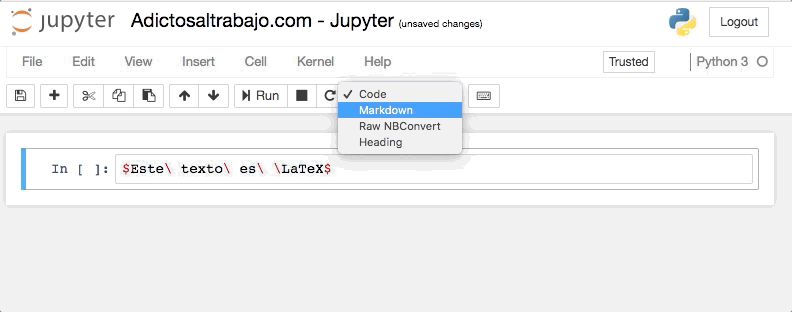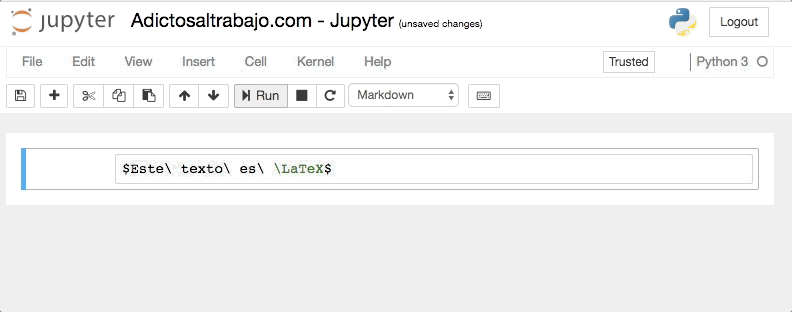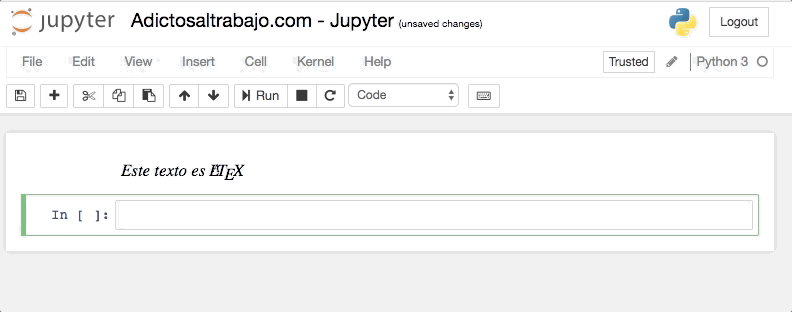
Para mostrar código LaTeX en nuestro cuaderno, simplemente tenemos que escribir entre dólares (simples o dobles, según queramos), y marcar la celda como texto plano (Markdown).
 Otros lenguajes
Otros lenguajes
Para poder trabajar en Jupyter con otros lenguajes, se han desarrollado diferentes _kernels_. Los más utilizados, aparte del propio python, son:
- Haskell: kernel ihaskell.
- Javascript: kernel ijavascript.
- Julia: kernel ijulia.
Una vez instalados, simplemente seleccionamos el kernel deseado en la barra de menú de Jupyter.
Gráficas
La librería matplotlib.pyplot nos ofrece multitud de opciones a la hora de trabajar con gráficas, desde pintar varias funciones en la misma figura, con diferentes colores o diseños, hasta indicar por ejemplo el máximo de una función.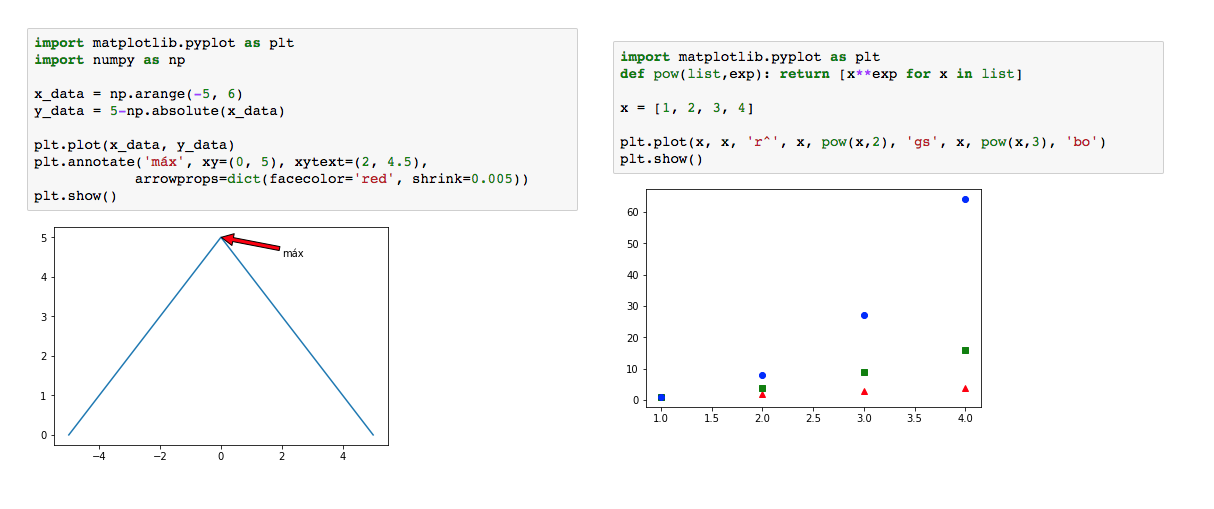 Texto
Texto
Varias cosas referentes a la escritura de texto plano:
- Como se ha mencionado antes, se debe indicar que el tipo de celda es Markdown.
- Podemos separar el contenido del documento con cabeceras para secciones, subsecciones, subsubsecciones… Es tan fácil como añadir de una a cinco almohadillas (#) al principio de la línea, tantas como el nivel que queramos tenga el título.

- Podemos añadir imágenes, indicando anchura, alineación, etc., con el comando
1<img src=‘…’ align=«…»>
- Si queremos mostrar una lista, con guión + espacio se formateará correctamente.
- ¡Podemos incluso añadir emojis